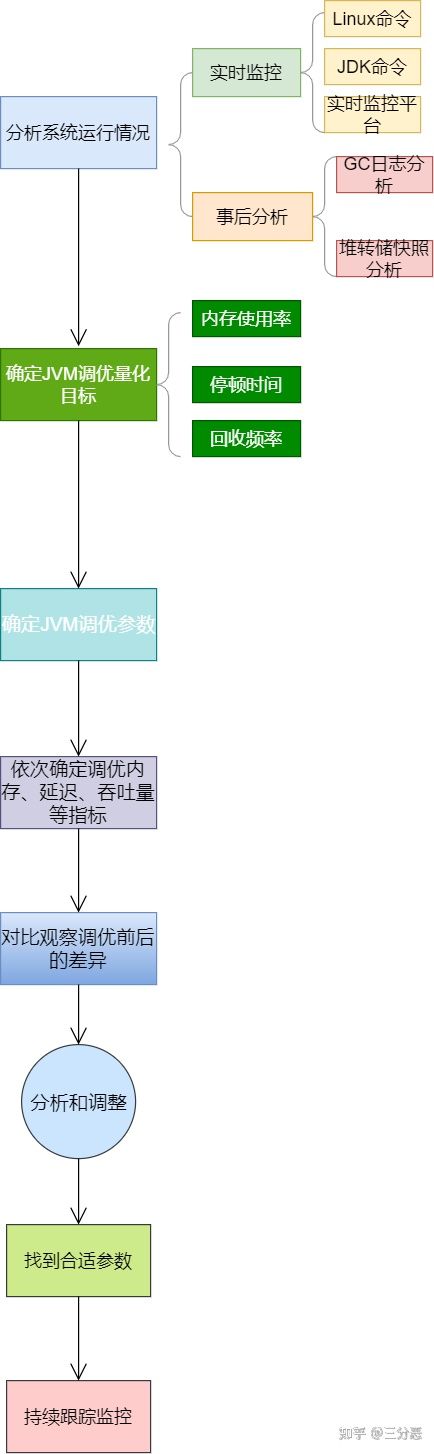
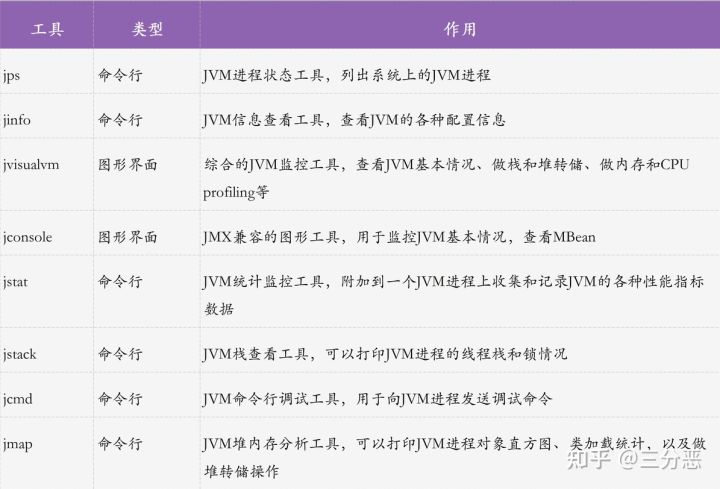
写作时,我们可能遇到系统故障,比如CPU使用率飙升或内存溢出等问题。在这种情况下,不能盲目进行JVM调优。相反,我们需要全面监控,并对性能数据做深入分析。
CPU飚高定位
系统上线后,CPU利用率持续攀升至600%,亟需查明是哪个应用导致。使用top命令排查,发现一个java应用耗用了600%的CPU资源。这就像在人群中找出那个“麻烦制造者”,确定了问题应用,为后续的排查工作指明了道路。
//设置Serial垃圾收集器(新生代)
开启:-XX:+UseSerialGC
//设置PS+PO,新生代使用功能Parallel Scavenge 老年代将会使用Parallel Old收集器
开启 -XX:+UseParallelOldGC
//CMS垃圾收集器(老年代)
开启 -XX:+UseConcMarkSweepGC
//设置G1垃圾收集器
开启 -XX:+UseG1GC
堆内存信息探查
//设置堆初始值
指令1:-Xms2g
指令2:-XX:InitialHeapSize=2048m
//设置堆区最大值
指令1:`-Xmx2g`
指令2: -XX:MaxHeapSize=2048m
//新生代内存配置
指令1:-Xmn512m
指令2:-XX:MaxNewSize=512m
//GC停顿时间,垃圾收集器会尝试用各种手段达到这个时间
-XX:MaxGCPauseMillis
发现问题尚未解决,于是我们转向堆内存信息这一方面。通过设置参数 -XX:+HeapDumpOnOutOfMemoryError,我们可以获取到堆内存的dump文件。这相当于拥有了“问题日记”,详细记录了堆内存的状态,有助于我们进一步分析问题,找出具体是哪里出现了问题。
//survivor区和Eden区大小比率
指令:-XX:SurvivorRatio=6 //S区和Eden区占新生代比率为1:6,两个S区2:6
//新生代和老年代的占比
-XX:NewRatio=4 //表示新生代:老年代 = 1:4 即老年代占整个堆的4/5;默认值=2
GC情况排查
//进入老年代最小的GC年龄,年轻代对象转换为老年代对象最小年龄值,默认值7
-XX:InitialTenuringThreshol=7
首先检查GC状态,若一切正常,接着从线程层面进行排查。通过执行jstat -gc PID命令输出GC数据,发现机器仅运行了短短几分钟,GC耗时已达到482秒。这一现象说明频繁的GC操作导致了CPU使用率急剧上升,就好比机器内某个部件过度工作,必然会出现问题。现已锁定问题的关键所在。
//新生代可容纳的最大对象,大于则直接会分配到老年代,0代表没有限制。
-XX:PretenureSizeThreshold=1000000
线程代码分析
分析线程时,发现了一些正在执行的业务线程。随后,我深入代码,注意到一个导出订单信息的功能。这就像追踪到可疑线索,可能正是这个功能的代码出现了性能瓶颈,进而影响了整个系统的运行。
//使用多少比例的老年代后开始CMS收集,默认是68%,如果频繁发生SerialOld卡顿,应该调小
-XX:CMSInitiatingOccupancyFraction
//G1混合垃圾回收周期中要包括的旧区域设置占用率阈值。默认占用率为 65%
-XX:G1MixedGCLiveThresholdPercent=65
内存调整推测
内存经过之前的优化和扩充,估计这或许导致了垃圾回收(GC)的单次耗时增加,进而可能引发系统的不稳定。这种现象并不罕见,就好比给车辆装载了过多的物品,行驶起来自然会感到不顺畅。因此,内存升级后也可能出现新的问题,我们需要深入研究并探讨如何进行相应的调整。
XX:MaxDirectMemorySize
堆内存离线分析
将内存中的数据导出,随后用visualVM进行离线查看。首先关注内存使用量最大的对象,排在第三位的业务VO占据了大约10%的堆内存,这显然不正常。这就像在人群中发现了那个体型特别大的个体,找到了内存消耗异常的“嫌疑人”,有助于我们进一步追踪和解决问题。
在JVM优化过程中,你是否遇到过类似难题?若有所得,不妨点个赞,并将经验分享给其他朋友。